Jako každý rok se i letos mohli studenti FIT ČVUT zúčastnit VýLeTu neboli Výzkumného léta na FIT, programu, který podporuje motivované studenty v jejich vlastním vědeckém výzkumu. Co účast na VýLeTu konkrétně obnáší? Celý program je rozdělený na 3 etapy. Výstupem 1. etapy, která probíhá v letních měsících, je úvodní studie k projektu formou rešerše nebo rozpracovaného článku. Jako výstup 2. etapy, která se koná v zimním semestru, už účastníci odevzdávají výstup připravený k publikaci nebo uplatnění. Typicky se jedná o příspěvek na konferenci nebo článek do vědeckého časopisu. V závěrečné části pak o výsledcích svého výzkumu sepíší popularizační článek (na konci minulého ročníku byly tyto články publikované na portálu medium.com). Zajímá vás víc? Možná taky uvažujete, že byste se do programu přihlásili, ale nejdřív byste si rádi poslechli konkrétní zkušenosti studentů před vámi? Pak čtěte dál. Vyzpovídali jsme totiž pro vás 4 účastníky letošního ročníku – Elišku Svobodovou, Hermana Tiumentseva, Michala Dvořáka a Tomáše Chobolu.
Anička: Jak VýLeT během pandemie koronaviru probíhal? Pracovali jste hlavně z domova?
Michal: VýLeT začal už v létě. V té době už byla první vlna koronavirové pandemie na ústupu, takže jsme měli možnost pracovat přímo na FITu. Sám jsem však VýLeT dělal většinou z domova, protože má práce byla taková teoretičtější. Všechny konzultace jsem absolvoval vzdáleně.
Tomáš: Já jsem pracoval mimo Prahu.
Eliška: Také distančně. Kromě úvodní schůzky a workshopu o tom, jak se píše rešerše, která je zakončením první iterace.

Herman Tiumentsev na FITu studuje 3. ročník bakaláře obor Znalostní inženýrství. Jako téma svého výzkumu si zvolil rozpoznávání textu v historických archiváliích ze 17. až 19. století. Vedoucího práce mu dělá Ing. Jiří Smítka.
Anička: Jaké je ve zkratce téma vašeho výzkumu?
Herman: Moje práce se zabývá rozpoznáváním textu v historických archiváliích. Využívám data z Národní knihovny, ze kterých jsem vytvořil dataset o 2000 symbolech, na kterém teď učím neuronovou síť rozpoznávat text. Dokončil jsem první etapu, druhou jsem nestihl. Tak doufám, že brzy stihnu článek dokončit a prezentovat ho na konferenci SSIP 2021, která se bude konat v létě. Teď také na téma svého výzkumu píšu bakalářku. Jsem moc rád, že jsem na celém projektu začal pracovat brzy.

Anička: Eliško, ty také budeš mít z výzkumu v rámci VýLeTu bakalářku, nepletu-li se?
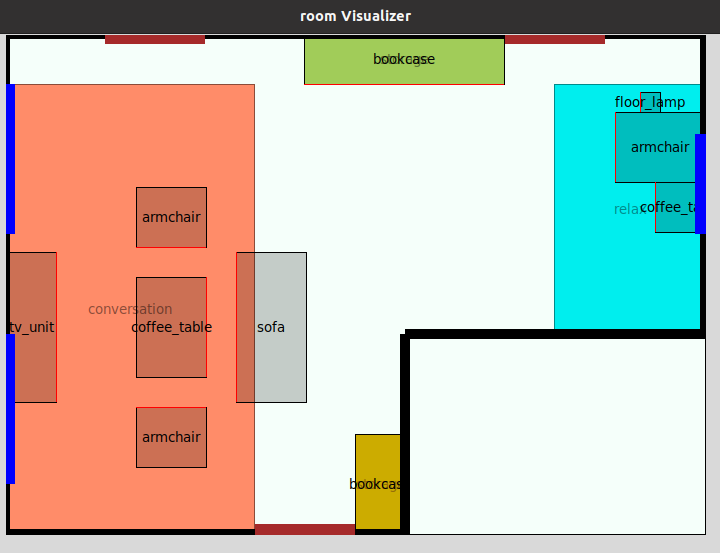
Eliška: Přesně tak. Zabývám se automatizovaným interiérovým designem a mým cílem je vyvinout systém, který vezme požadavky od uživatele jako například tvar místnosti, umístění oken a dveří, jednotlivé druhy nábytku, k čemu má místnost sloužit… Systém by potom měl vybrat zbytek nábytku, rozmístit ho, aby se nepřekrýval, a obecně ho naaranžovat tak, aby rozmístění dávalo v prostoru smysl.
Anička: Jakpak to máš dělané? Rozhodla jsi se pro neuronku, nebo nějakou klasičtější metodu?
Eliška: Tento obor (architektura, pozn. red.) má velký problém s daty. Nemáme velké datasety, takže jsem skončila u simulovaného žíhání a genetického algoritmu, protože ty nepotřebují moc dat.
Kristýna: Takže na to žádný větší dataset prostě neexistuje?
Eliška: Nějací výzkumníci zkoušeli přístup postavený na datech, kdy využívali dataset SUNCG. Ale bohužel k němu začala tahanice o autorská práva.

Eliška Svobodová na FITu studuje 3. ročník bakaláře obor Softwarové inženýrství. Pod vedením Ing. Mgr. Ladislavy Smítkové Janků, Ph.D. zkoumá vybavení interiéru nábytkem pomocí metod umělé inteligence.
Anička: Copak to bylo za dataset – fotky, půdorysy?
Eliška: Pohledy shora na 3D místnosti. Z nich se výzkumníci snažili dostat vztahy mezi objekty a naučit například GANy, aby to dokázaly napodobit.
Kristýna: GANy jako Generative adversarial networks? Používané třeba tak, že jedna neuronka vytváří fake fotky a druhá se je snaží odhalit?
Eliška: To je přesně ono.


Kristýna: A čím se zabýváš ty, Michale?
Michal: Já mám trochu matematičtější a teoretičtější téma – Mathieuovy funkce. Asi bych měl vysvětlit, co to vůbec je. Existují funkce, které se definují například jako řešení diferenciální rovnice a nejdou vyjádřit pomocí elementárních funkcí, jako je třeba exponenciála, sinus, … Otázka je, jak se s tím vypořádat, když potřebujeme takové funkce počítat. Výsledkem mého snažení má být balíček v jazyce Julia, který počítá hodnoty Mathieuových funkcí. A důvod, proč se tím zabývat, je jednoduchý. Žádná uspokojivá implementace neexistuje.
Kristýna: Jak jsi daleko?
Michal: Napsal jsem rešerši, která byla hlavně pro mě, abych vůbec zjistil, co to téma znamená. Druhá etapa je zatím otevřená.

Michal Dvořák na FITu studuje 3. ročník bakaláře obor Teoretická informatika. V rámci VýLeTu se zabývá problematikou Mathieuových funkcí pod vedením lektora Ing. Tomáše Kalvody, Ph.D.
Anička: A co ty, Tomáši?
Tomáš: Já jsem si projel VýLeTem od začátku až do konce. Můj projekt se zabýval Few-Shot Learningem, což je přístup ke strojovému učení používaný v situacích, kdy máme opravdu málo dat (např. jednu nebo dvě instance). To je v kontrastu s klasickým strojovým učením, ve kterém se typicky používají kvanta dat. Je to teď nový způsob jak vytvářet machine learning modely v oblastech, ve kterých je získávání dat složité.
Kristýna: Na projektu tedy už nepracuješ? Co konkrétně jsi vytvořil?
Tomáš: VýLeTem jsem ukončil mé působení na FITu, nyní studuji magistra na zahraniční univerzitě. Spolu s Pavlem Kordíkem a Danielem Vašatou jsme vyvinuli Few-Shot learning model, s kterým jsme se účastnili soutěže v rámci workshopu pořádaného konferencí AAAI. Díky úspěchu našeho modelu jsme v únoru na letošním ročníku této konference odprezentovali naše výsledky.

Bc. Tomáš Chobola minulý rok bakalářské studium na FITu úspěšně dokončil a aktuálně pokračuje v magisterském studiu na TU Munich. Ve své práci se soustředil na Meta-learning methods a na Few-Shot Classification. Spolu s mentory doc. Ing. Pavlem Kordíkem, Ph.D. a Ing. Danielem Vašatou, Ph.D. vytvořil Few-Shot Classification model, s kterým se účastnili soutěže pořádanou organizátory MetaDL workshopu na konferenci AAAI 2021. V této soutěži se umístili na druhém místě a dostali tak pozvánku prezentovat svou práci na této konferenci. Jejich práce bude také součástí příštího vydání PMLR proceedings. Detaily o projektu si můžete přečíst v popularizačním článku, který Tomáš sepsal.
Anička: Jak váš model ve zkratce funguje?
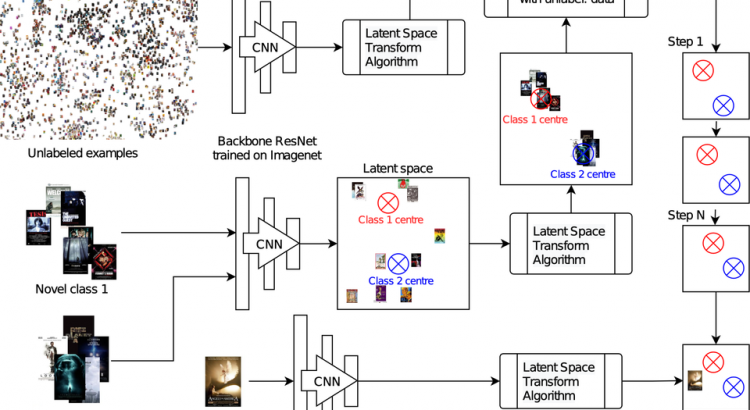
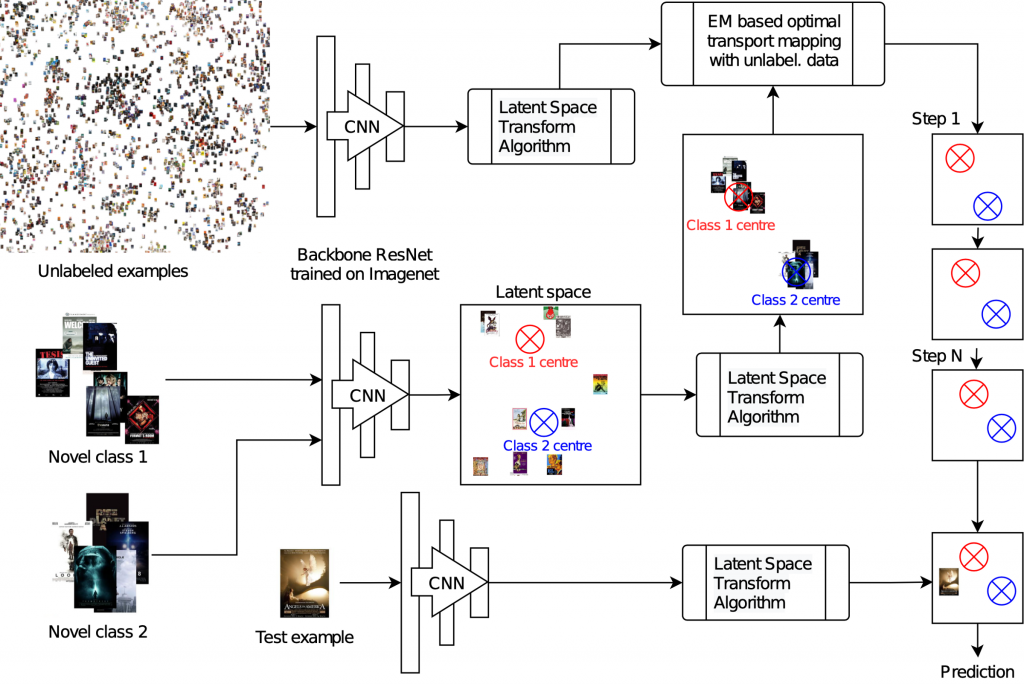
Tomáš: Náš model se skládá ze dvou částí. První část – neuronová síť, se naučí, jak rozpoznávat objekty. Účelem sítě je rozpoznat charakteristiky objektů na obrázcích a následně rozhodnout, jestli jsou objekty stejné nebo ne. Z toho získáme zakódování obrázků (embeddingy), které pošleme jako vstup druhé části modelu.
Druhá část modelu – matematický model, se v průběhu několika iterací snaží odhadnout centra jednotlivých tříd, která jsou v první iteraci inicializovaná pomocí trénovacích instancí (těch máme jen pár, proto se metodě říká few-show learning). V každé iteraci dochází k namapování instancí, u kterých nemáme label, a které tedy chceme klasifikovat, na tato centra. Každá interace aproximuje centra na základě namapovaných instancí, a proto celý proces probíhá v několika krocích, čímž by mělo dojít k co nejlepší aproximaci center jednotlivých tříd.
Toto namapování je docela obtížný úkol. Ale je to zároveň jeden z nejlepších přístupů k Few-Shot Learningu, který aktuálně máme. A my jsme v rámci našeho výzkumu s Pavlem Kordíkem a Danielem Vašatou tento přístup ještě vylepšili. Přidali jsme do modelu dva regularizační parametry, které pracují se sílou mapování a regularizací. V soutěži nám to stačilo na druhé místo, i když nevím, proč ne na první. (smích)
Kristýna: Takže je to vlastně přístup podobný tomu, který se využívá například ve zpracování přirozeného jazyka, kde se také nejdříve získají embeddingy kódující text a ty se pak používají na nějaký konkrétní úkol?
Tomáš: Tak, tak. Ta první část modelu je takový backbone, aby se získaly hlavní informace, a tu samotnou klasifikaci pak dělá ten matematický model.
Anička: Jak probíhala prezentace vašich výsledků na konferenci?
Tomáš: Konference se měla konat ve Vancouveru, ale kvůli současné covidové situaci byla online. Bohužel jsme tedy nikam nejeli. Na workshopu jsme měli vyhrazený slot, kde jsme prezentovali naše řešení. Pak jsme ještě měli připravený plakát prezentovaný v rámci poster session.
Anička: Přes jakou platformu to bylo organizované?
Tomáš: Všechno to bylo udělané přes Zoom místnosti. Byla to zajímavá zkušenost, třeba už jen tím, že se konference zúčastnily významné osobnosti z oboru strojového učení.
Kristýna: Teď bych na vás všechny měla otázku, jak velká práce je sepsat článek? Vnímáte to třeba tak, že samotný výzkum je legrace a sepsání článku je pracné?
Tomáš: Mně to nepřišlo nějak obtížné. Hlavně se jedná jen o pár stránek. Je tam úvod, celá stránka s referencemi, nějaké obrázky…. Není to tak náročné obzvlášť v porovnání s bakalářkou, která zabere semestr. My jsme dokonce článek psali všichni tři, kdo jsme se na výzkumu podíleli, společně. Potřebovali jsme stihnout deadline odevzdání na konferenci. Psaní článku v rámci VýLeTu vnímám jako skvělou příležitost, se kterou se jinak člověk na FITu moc nesetká.
Herman: Já jsem to psal asi 3 dny, ale předtím jsem to skoro měsíc rozpracovával. Hledal jsem články, snažil se najít co nejrelevantnější informace… A pak téměř v den deadlinu jsem to celé zformuloval a poslal vedoucímu. (smích)
Eliška: Já jsem ráda, že slyším, že všichni psali článek na poslední chvíli. U mě to bylo úplně stejné, taky jsem to dávala dohromady tři dny před deadlinem. Chci ale vypíchnout, že těm třem dnům předcházel půlrok plný implementace a testování mého systému.
Kristýna: Takže se studenti nemají bát, že je součástí VýLeTu nějaké psaní článku?
Tomáš: To nemají.
Michal: Minimálně je určitě čeká bakalářka. Sbíral jsem všechny články, psal jsem si poznámky a když jsem je trochu okrouhal, tak z toho byl článek. Takže za mě to také bylo v pohodě. Je to celkem krátké. Článek jsme dokonce s vedoucím mé práce Tomášem Kalvodou psali společně.
Kristýna: Na závěr se vás chceme zeptat, kdybyste se vrátili v čase a už věděli, co očekávat, šli byste do toho znova? Zúčastnili byste se VýLeTu?
Herman: Myslím, že jo. Byla to zajímavá zkušenost. Chtěl bych výzkumu věnovat více času. VýLeT je skvělá možnost.
Michal: Za mě je dost složité prolomit bariéru mezi rešerší a článkem. Třeba v matematice je skutečně těžké přijít s něčím novým. Kdybych ale našel téma, kde by mě napadlo něco revolučního, tak proč ne. A je skvělé, že se díky tomu připravíme na bakalářku, diplomku… Nejde o peníze a odměny, ale o to, že se člověk naučí pohybovat ve vědecké oblasti.
Eliška: Mám už dokonce zarezervované téma i na příští ročník VýLeTu. Systém bych chtěla dále rozšiřovat.
Tomáš: Já teď za sebou mám už druhé kolo VýLeTu – takže myslím, že to samo o sobě odpovídá na otázku. (smích) VýLeT je skvělá příležitost, která kombinuje praxi, matematiku a programování.
Autorky:
Anna Sajdoková, Kristýna Klesnilová
Foto:
medailonky – osobní archivy zpovídaných
[1] osobní archiv Hermana Tiumentseva
[2] osobní archiv Elišky Svobodové
[3] článek Tomáše Choboly na portálu medium.com