Věděli jste, že koncept neuronových sítí je starší více než 80 let? Přesto se o nich pořád mluví, jako by to v oblasti AI bylo něco žhavě nového. O tom, jak neuronka funguje, se dnes tolik bavit nebudeme. Přečíst si o tom můžete například v lednovém článku. Místo toho se ale podíváme, jak se tyhle věcičky používají v praxi. Vybrali jsme několik inspirativních projektů, jako je síť, která dokáže diagnostikovat covid z rentgenu, či neuronka na generování hudby, na kterých pracují studenti FITu a kteří nám svou tvorbu na následujících řádcích představí.
Martin Vojtíšek
Znáte to, bolí vás hlava, navíc se vám ráno špatně vstávalo, tak si jdete vygooglit, co by vám mohlo být. Po pár minutách čtení na webu zjišťujete, že máte asi 5 smrtelných nemocí a že je nejvyšší čas vyhledat notáře na sepsání závěti. Tak přesně tohle chce Martin změnit.
Martin je teprve v prvním ročníku bakaláře, přesto se nebál zapojit do výzkumné skupiny ML-CIG, ve které pracuje na takzvaném klasifikátoru medicínských dotazů pro web ulekare.cz. Myšlenka je taková, že uživatel přijde na web, do kolonky napíše svou otázku nebo nějaký zdravotní problém a software pak sám vyhodnotí, do jaké z 41 kategorií tento dotaz spadá a jaký specialista by se tedy měl otázce věnovat.
Jak ses k projektu dostal?
Se strojovým učením jsem trochu blbnul už na střední. Když jsem přišel na FIT, zjistil jsem, že je tu výzkumná skupina ML-CIG. Jejím vedoucím je pan docent Kordík, proděkan pro spolupráci s průmyslem. Ten mi poradil, že nejlepší způsob, jak získat praxi, je prostě skočit do vody a osahat si to na reálných projektech. Tak jsem se chytl téhle možnosti vyvíjet klasifikátor pro ulekare.cz přes fakultu a šel do toho. Jinak mi hodně s celým projektem ještě pomohl Adam Jankovec, který dělal na druhém projektu pro stejnou firmu.
Jak si neuronku učil?
Na začátku jsem od té firmy dostal databázi se vzorovými otázkami, které už byly rozřazené do kategorií. Protože většina algoritmů, které jsem chtěl použít, neumí moc dobře fungovat se znaky a mají radši čísla, vygeneroval jsem si jednoduchý slovník převádějící slova na čísla. Nad zakódovanými otázkami jsem postupně vyzkoušel 3 různá řešení. Neuronovou síť s embedding a attention mechanizmem, potom jednoduchou menší síť, do které vstupovaly otázky ještě zakódované přes algoritmus tf-idf, a v neposlední řadě kódování typu „bag-of-words“, také se stejnou feedforward sítí, což se nakonec ukázalo jako nejlepší řešení. Jinak při implementaci jsem používal knihovny Tensorflow a scikit-learn, obojí je takový průmyslový standard pro machine learning.
Jak dlouho na tom pracuješ a kdy to uvidí světlo světa?
Pracovat jsem na tom začal až někdy na konci zimního semestru, zhruba o Vánocích. Výhodou bylo, že jsem to neviděl úplně poprvé, měl jsem už předchozí zkušenosti se zpracováním textu. Zatím se mi to podařilo vyladit na nějakou 80% úspěšnost, což není úplně špatné. Největší problém je s podobnými kategoriemi, třeba chirurgie a vnitřní lékařství – jsou tam obdobná slova. Pro lékaře je to sice jasně odlišitelné, ale ten stroj s tím pořád má trochu problémy. Jinak je to skoro hotové a teď v březnu se budeme domlouvat na nasazení.
Bude se síť poté sama učit za pochodu?
Online learning za běhu by šel, ale bylo by to náročné z hlediska infrastruktury webu. Navíc je to docela náchylné na nějakou negativní zpětnou vazbu. Kdy třeba nějaký naštvaný uživatel bude schválně zadávat podivná data, nebo do toho sáhne nešikovný administrátor. Lepší alternativa je po čase tu síť zase přetrénovat u sebe na aktualizovaných datech.
Jirka Hany Hanuš
Kdo nezná Mistra Hanuše, jako by FIŤákem nebyl. Hany má na svém kontě rovnou dva projekty s využitím neuronek. Prvním je síť na generování hudby. Vedle toho Hany aktuálně pracuje na diplomové práci – virtuálním pianu, které se ovládá pomocí technik zpracování obrazu.
Hany, proč zrovna generování hudby?
Tohle téma jsem si vlastně vybral jako semestrální práci v předmětu NI-MVI (Metody výpočetní inteligence). Našel jsem si článek na generování Pokemon hudby právě pomocí neuronek, kterým jsem se inspiroval. Měli tam zveřejněný i kus kódu na GitHubu. Ten jsem si stáhnul a hodně předělal podle svých potřeb. V prvních pokusech se mi povedlo generovat nějaké náhodné noty, které ale byly stejně dlouhé. Takhle jsem to odevzdal jako seminárku a to nebyla žádná hitparáda. No a pak jsem zjistil, že s tím parametrem délky jsem vůbec nepracoval, takže jsem to přidal a teď už tvoří celkem přesvědčivou hudbu. Dokonce jsem to prezentoval na online meetingu, ktery se věnoval umělé inteligenci a který pořádala Apsatory, partnerská společnost Googlu.
Jakou technologii jsi na učení svojí neuronky používal?
Vlastně jsem učil dvě neuronky pomocí GAN metody. To znamená, že máš dvě sítě, co soupeří proti sobě a tím se učí. Jedna je ten generátor hudby, který se snaží vytvořit co nejlepší hudbu prakticky z ničeho, takže ze začátku jsou to jen nějaké náhodné noty. A pak máš druhou síť, které se říká diskriminátor. Tomu předhodíš buď tu reálnou hudbu od člověka, nebo právě výtvor generátoru, ovšem on předem neví, co z toho to je, a jeho úkolem je to rozpoznat. A tyhle dvě sítě spolu vlastně soupeří. Když diskriminátor pozná, že vstupní hudba se liší od lidských ukázek a je to tedy výtvor generátoru, generátor se z toho poučí, že tudy cesta nevede a má hudbu tvořit jiným způsobem.
A když to nepozná?
Když generátor podstrčí vlastní noty a diskriminátor si myslí, že je to od člověka, je to pro první síť signál, že takhle to dělá správně. Naopak diskriminátor se sám pošteluje tak, aby se příště nenechal napálit. A takhle se vlastně ty dvě sítě učí navzájem.
Pak jsem k tomu ještě přidal LSTM. To znamená, že se jeden neuron nahradí čtyřmi a díky tomu získá neuronka krátkodobou paměť a drží si nějaký kontext. Takže když jí zahraješ nějaké písničky, tak si pamatuje, že po tomhle tónu je pěkné hrát tenhle jiný tón a snaží se to reprodukovat i do svých výtvorů.
Jak probíhalo samotné učení?
Důležité je, že na začátku jsem připravil hudbu jako .midi soubory. Bylo by totiž těžké, abys dal neuronce na začátku prostě jen proud hudby, zvuku, se snímkováním třeba 44 Hz. Z toho by byla akorát strašně zmatená a generovala by nesmysly. V .midi souborech už máš označené věci jako ‘aha, teď hraješ déčko, je dlouhé 5 vteřin’. Takže na začátku jsem měl balíček nějakých 230 vzorových songů. Ty jsem si nejdřív musel nějak namapovat přes tóny, že třeba C bylo nějaké číslo, abych to mohl vkládat do sítě. A pak právě probíhá proces učení, kde postupně neuronce dáváš třeba tři písničky najednou a ona si podle toho nastaví váhy neuronů v cestě, kudy šla ta písnička. A pak už jí jen předhazuješ nějaké začáteční tóny a ona ti podle toho tvoří úplně nové písničky.
Velmi zajímavé. Povíš nám ještě něco o tvém druhém projektu, virtuálním pianu?
To je vlastně diplomka, kterou teď do května musím mít hotovou. Představuji si to tak, že člověk si prostě vytiskne A4ku se dvěma oktávami kláves, nastaví si na sebe kameru a hraje.
Jak to funguje?
Jde tam o zpracování obrazu, jednak pomocí RGB kamery, co máme každý na noťasu nebo mobilu. A pak na to ještě používám speciální Leap Motion Controller pro 3D snímání. Ten funguje tak, že na tebe promítá nějaký infračervený vzor, mřížku a na té kameře jsou pak 2 infračervené snímače. A podle toho, jaká je distorze toho vzoru, se určuje vzdálenost a rotace objektu. Takže ti ten Leap motion pak hezky dá informaci o tom, kde máš třeba nějaký článek prstu nebo jeho špičku. A právě když se špička dotkne papíru, což je ta nejtěžší část – poznat, kdy přesně se dotkla – tak se zahraje tón.
V jaké fázi vývoje jsi?
Teď už mám nějak hotové rozpoznávání gest za pomoci RGB kamery. Ovšem, často je to náchylné třeba na světelné podmínky nebo otočení ruky o pár stupňů. Takže teď budu dělat tzv. „data augmentation“, kdy ten základní dataset, ze kterého neuronku učím, rozšířím o další varianty různě natočených rukou, různě nasvětlených atd.
Jinak učit ji budu vlastně nadvakrát – jednou jenom z toho 2D obrázku z RGB kamery, no a napodruhé i pomocí toho Leap Motionu, kde nějaké světelné podmínky už nehrají takovou roli.
A ve výsledku bych chtěl, aby to fungovalo buď jenom s jednou z těch kamer, nebo s obojím dohromady. To rozpoznávání polohy je vlastně ta nejtěžší část. Pak už jen pomocí nějaký knihovny, třeba z PyGame, udělám, že to bude hrát a ukládat do .midi souboru.
Na závěr bych rád podotknul, že v celém projektu mi hodně pomohla knihovna OpenCV, kterou jsem poznal na BI-SVZ.
Jan Peřina
Honza pracuje v rámci své bakalářky na software, který detekuje, jestli část textu byla přeložená z cizího jazyka.
Čím přesně se zabýváš ve svém projektu?
Už dlouho mě zajímá zpracování přirozeného jazyka v kombinaci s machine learningem. V rámci bakalářky pracuji na programu, který dostane text v češtině, a snaží se rozpoznat, jestli nějaká jeho část vznikla přeložením z cizího jazyka pomocí strojového překladu – například za pomoci služby Google Translate. To se může hodit třeba při odhalení plagiátorství. Jeden z cílů práce je i možnost automaticky dohledávat nějaké potenciální zdroje, ze kterých byl text přeložený, na internetu pomocí klíčových slov z těch detekovaných kusů textu. Práce na tom mě ale teprve čeká.
Jakou technologii používáš?
Jádrem jsou neuronové sítě, které dělají samotný překlad textu – tzv. neural machine translation models. V mém případě je to rekurentní neuronka, které dáš text zakódovaný do podoby, které rozumí. Ta ti pak vygeneruje zakódovaný překlad do druhého jazyka a ten pak stačí jen obdobně dekódovat.
Dále používám klasifikační model, na základě kterého rozhodnu, jestli je část textu přeložená, nebo ne. Aktuálně jich zkouším víc a snažím se zjistit, který na to bude nejlepší. Ty klasifikátory učím na česko-anglických textech, respektive podobnostním score (metrice) mezi dvěma verzemi textu v češtině. Jde o metriku, která byla původně vyvinuta za účelem měření kvality strojového překladu oproti tomu lidskému, ale perfektně se to hodí právě i do mého projektu.

Jak to funguje?
Vycházel jsem z článku ve kterém už tahle metoda tzv. „back translation“ byla implementována v anglicko-španělské verzi. Celé je to založené na tom, že když máš třeba český text a přeložíš ho strojově do angličtiny, tak překlad zpátky do češtiny bude trochu jiný než originál. Když bys takhle s překladem tam a zpátky pokračoval, tak by se ty rozdíly mezi texty postupně vlivem překladače zmenšovaly, až bys nakonec došel do bodu, ve kterém by byly identické. A tuhle odlišnost/podobnost mezi dvěma generacemi překladu textu v jednom jazyce si pak pomocí té zmíněné metriky můžeš změřit od 0 do 1 a použít v těch klasifikátorech.
Takže neuronka ty texty postupně nějak překládá?
Přesně tak. Na začátku se vezme text ve zdrojovém jazyce např. češtině a přeloží se do jiného jazyka – pro jednoduchost do angličtiny a pak zase zpátky. Potom se měří podobnost mezi tím původním a nově vzniklým textem pomocí té metriky.
Tuto operaci provedu na nově vzniklém českém textu ještě šestkrát a na konci mám sedm čísel, ve kterých je nějakým způsobem zachycená stopa po překladači – v každém dalším čísle o něco větší.
Takže pokud takhle přeložím originální text, ta stopa bude podstatně menší než u už přeloženého textu. A tuhle stopu se vlastně snaží odhalit ten klasifikátor. Samozřejmě je to ale jen část toho algoritmu, ještě je třeba vymyslet způsob, kterým spojím ty detekované části a budu pro ně hledat originál.
Jakub Žitný
Kuba je doktorand z FITu, kterého zná spoustu studentů, především prváků, díky fakultnímu portálu LearnShell využívanému ke zkoušení z předmětu BI-PS1. Podle jeho slov tento projekt ale jenom „zachraňuje“, a to na co se nejvíce zaměřuje, je využití umělé inteligence v oblasti diagnostiky v lékařství.
Jaké je tvoje téma?
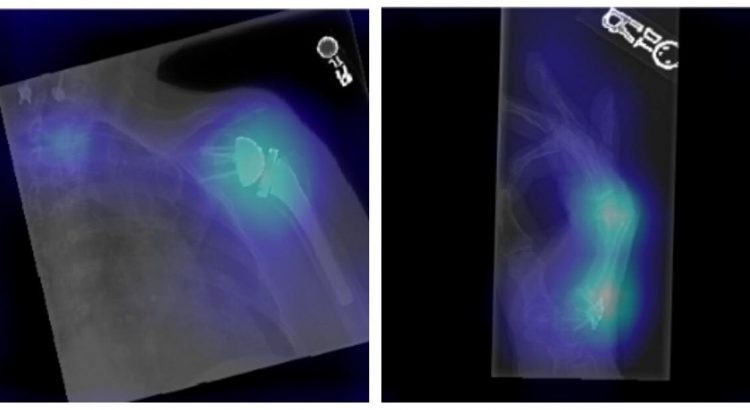
Zaměřuji se na interpretaci konvolučních neuronových sítí, hlavně v oblasti medicínských dat. To znamená, že používám celkem moderní neuronky k diagnostikování nějakých vad na snímcích z CTčka, rentgenu nebo magnetické rezonance. Nebo na různé klasifikace – třeba jestli je nějaká kost zlomená, jestli je nádor zhoubný atd. Mimo to mě ale také hodně zajímají generativní modely, což je teďka takový hot topic. Jde o software, který generuje nějaká nová data, co neexistují, například vytvoří úplně nový obličej člověka. To pak typicky používám k „data augmentation“, tedy rozšíření datasetu, který obvykle v medicíně nebývá dostatečně velký.
Rentgenový snímek, na kterém neuronová síť vyznačila oblast s kostními abnormalitami; zdroj: https://dspace.cvut.cz/handle/10467/88175

Pracuješ třeba na nějakých projektech přes fakultu?
Na FITu jsem ve výzkumné skupině CIG-ML, což je široká výzkumná skupina, která se zabývá tématy od optimalizace přes chatboty až po machine learning. Já jsem v některých menších týmech této skupiny, ale většinu času si tak nějak pracuji na projektech, co si vyberu sám, třeba ty sítě na analýzu snímků z rentgenu. Díky tomu například spolupracuji s jedním diagnostickým centrem na Slovensku, které mi poskytuje různá data. Na internetu je sice hodně open-source medicínských dat, na kterých se sítě můžou natrénovat, ale zrovna v mém případě jsou to dost specifická data, která moc k nalezení nejsou. Ještě bych dodal, že na některých projektech spolupracuji s dalšími studenty z ČR i zahraničí.
Jestli to správně chápu, tak sítě, které vyvíjíš, dokážou rozpoznat třeba nějaký nádor na snímku místo doktora?
Skoro ano. Reálně to nefunguje úplně tak, že ta sít nahradí člověka, to by bylo mnohem komplikovanější. Moje neuronka se ale dá zahrnout do nějakého diagnostického softwaru, který má pak takovou poradní funkci. Takže v praxi když máš třeba nějakého diagnostika na oddělení s magnetickou rezonancí, lidé mu tam chodí jak na běžícím páse a na každého má maximálně 15 minut, tak tahle síť mu ta data dokáže už nějak předzpracovat, aby si mezi těmi snímky mohl rychle přepínat. Nebo mu zvýrazní nějaká podezřelá místa. Kolikrát jsou nádory nebo nějaké podobné vzory tak malé, že si jich doktor nedokáže včas všimnout, síť ale ano. Dokáže to třeba i u covidu, na rentgenových snímcích plic postižených touto nemocí jsou vidět nějaké závady a ta síť ti opět dokáže třeba říct, jak závažný je jejich stav.
Musel ses učit i něco z lékařství?
Tak samozřejmě čím víc bych tomu tématu rozuměl, tím líp se mi to bude dělat. Na těchto projektech ale pracuji i s dalšími studenty a skvělými lékaři ze zahraničí, kteří mi dokážou vysvětlit ten medicínský problém, takže se pak můžu soustředit čistě na technické řešení. Vím, jak ta data vypadají, na co se tam mám podívat, ale to je asi tak všechno.